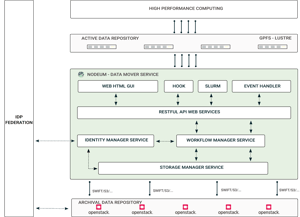
Research facilities have an automatic data mover engine which interoperate between the two different types of data repositories.
This ideal solution provides the following features to users:
- Organize the movement of the data from the Active to the Archival Data Repository
- Keep a direct access by the users to Active and Archival Data Repositories
- Integration with HPC workload managers like Slurm
- Provide a public API and SDK to facilitate integration with specific research applications
Federated cloud object stores are used at these locations ; in using standard Swift and S3 interfaces, they enable researchers to exchange their data. With the Data Mover, researchers can copy their data locally to the existing parallel file systems in order to process them on the fast HPC systems.
In addition, researchers can copy data, which have been generated on these supercomputers to the cloud object storage in order to make them accessible to other researchers from all over the world.