Stories
Read Stories to learn more about key Nodeum use cases, Industries, Values and Customers.
Supercomputing systems are so performant and scalable that the data generation speed has never been so fast. Research centers have to store the generated contents in "Data repositories" both are located close to each others and they are well integrated.
Two different categories of data repositories are used as storage tiers :
Active data repositories which provide the performance when data are written by supercomputing systems.
Archival data repositories which the capacity required to store all of these data.
The supercomputing infrastructure are base on scalable technologies. It is why data repositories capacity are exploding in term of contents and usage.
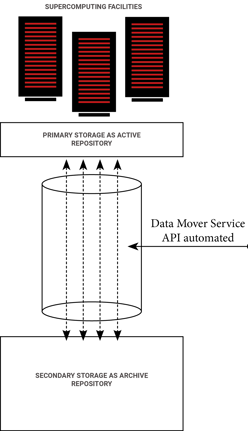
These facilities need to use an automatic data mover engine which will manage these two different type of data repositories. And provides the following features to users :
Manage the active storage
Organize the movement of the data from the active storage to the archive storage
Keep a direct access by the users.
Furthermore,
The solution have to manage every type of storage (NAS, Object Storage and Tape)
Provide a public API and SDK to facilitate the integration with the specific research application and reduce the IT infrastructure latency to access their files/data.